Saturday, March 1, 2008
Convert .eml files to .mbox (for Evolution import)
The Ruby script eml2mbox does it well. So, if you want to import a bunch of .eml files into Evolution, this should do it.
Friday, February 29, 2008
Firefox 3.0b3 in Ubuntu
This one comes straight from Rich Burridge's Blog: How to stop Firefox 3.0b3 in Ubuntu to move itself to the current virtual desktop when clicking a link:
browser.tabs.loadDivertedInBackground=True in about:config
Monday, February 18, 2008
Maemo icon sizes
I had a hard time finding out which icon sizes one has to provide and where to install them for Maemo applications (I'm currently developing for OS2008 "chinook", might be different for other releases). Here is what I found out by looking at the contents of other GUI packages:
26x26 icon goes to /usr/share/icons/26x26/hildon/appname.pngThe 64x64 icon will be used in the menu, so be sure to make it really 64x64, otherwise the icon will look out of place in the menu. Also, be sure to create an executable "postinst" file in the "debian/" subdirectory of your package source that has at least the following two commands:
40x40 icon goes to /usr/share/icons/40x40/hilson/appname.png
64x64 icon goes to /usr/share/icons/scalable/hildon/appname.png
gtk-update-icon-cache -f /usr/share/icons/hicolorWhere of course "appname" is the name of your application and how you named your icon and .desktop file.
maemo-select-menu-location appname.desktop
Thursday, February 7, 2008
gPodder Configuration Editor
I've had the idea of implementing some kind of about:config-like configuration editor for gPodder for some time now. Not only does it give a nice live view of the current configuration settings, it also makes it possible to edit some configuration values that were previously only available by editing
Apart from that, we might be able to strip down the preferences dialog to only the really important settings and leave everything else in the "advanced" configuration editor :) I think the interface is quite nice and even looks nicer than the real about:config editor. As with Mozilla's about:config editor, this also marks the settings that have been modified from their default value in bold.

~/.config/gpodder/gpodder.conf by hand.Apart from that, we might be able to strip down the preferences dialog to only the really important settings and leave everything else in the "advanced" configuration editor :) I think the interface is quite nice and even looks nicer than the real about:config editor. As with Mozilla's about:config editor, this also marks the settings that have been modified from their default value in bold.

Tuesday, January 29, 2008
Two nice N800 uses
Today was exam at university, and I downloaded a nice single-file Javascript-based HTML page with questions from previous exams. Proved useful: a simple webapp that can be used offline.
After the exam I went home, passing-by an irish pub with free w-lan. Didn't go in, but stood outside, taking out the N800 and connecting to the Internet from some street in Vienna. Neat!
After the exam I went home, passing-by an irish pub with free w-lan. Didn't go in, but stood outside, taking out the N800 and connecting to the Internet from some street in Vienna. Neat!
Sunday, January 27, 2008
SpeedTouch 5x6: Disabling dial-on-demand
If you want to have an always-on connection to the Internet with your SpeedTouch 5x6 modem/router (for example shipped with Aon Speed), you have to download the configuration file from the device (
If you have strange problems with DNS responses coming from the wrong IP, remove the corresponding
user.ini) and change demanddial=enabled to demanddial=disabled and then re-upload the configuration file.If you have strange problems with DNS responses coming from the wrong IP, remove the corresponding
ipadd line from the config file and re-upload it to your modem/router.
Friday, January 25, 2008
Finally: DSL at home
After about eight years (or were it nine?) with 64k at home, we finally upgraded to a 2Mbit ADSL line at home. This makes so much things easier and faster, wow. Of course, I had a whopping 6Mbit line in Vienna since mid-October already, but at the weekends, doing something on the Internet was just cruelsome slow.
The only downside: Now, when I accidentally hit a MySpace link, the extraordinarily stupid brain-damaged embedded music files start playing right away. With 64k, I still had enough time to quickly close the tab before the music loaded ;)
The only downside: Now, when I accidentally hit a MySpace link, the extraordinarily stupid brain-damaged embedded music files start playing right away. With 64k, I still had enough time to quickly close the tab before the music loaded ;)
Wednesday, January 23, 2008
Usability: Device Dock
Browsing Theme suggestions for Ubuntu 8.04, I found an interesting idea: Device Dock. The original author writes on this page:

I would even go so far and say it would be even cooler if we could make it so that unmounting is just a matter of dragging the icons either just out of the dock or somehow make it easy to unmount the devices by dragging them somewhere. That would clearly make using removable devices easier to use and leave the desktop uncluttered. I could also imagine some fancy animation for the icons, so you will get notified when a new device has been mounted. Maybe even hide and slide-in the dock when it's not used, so it could also be above other windows. Just some random thoughts :)
Here is my device dock, simple yet in principle should be quite effective, This allows someone to keep their desktop tidy no matter what device the mount and unmount from their computer, icons don't get muddled up yet you can still easily access your icons from the desktop.

I would even go so far and say it would be even cooler if we could make it so that unmounting is just a matter of dragging the icons either just out of the dock or somehow make it easy to unmount the devices by dragging them somewhere. That would clearly make using removable devices easier to use and leave the desktop uncluttered. I could also imagine some fancy animation for the icons, so you will get notified when a new device has been mounted. Maybe even hide and slide-in the dock when it's not used, so it could also be above other windows. Just some random thoughts :)
Monday, January 21, 2008
gPodder, the N800 and Bluetooth
I've just added support for Bluetooth File Transfer to the development version of gPodder. With this, you will be able to send (and convert) Video Podcasts from within gPodder directly to your Nokia Internet Tablet (or any other Bluetooth device). Of course, there is also support for converting videos before they are transferred over Bluetooth, so you will have good performance on the device, independent on which format the Video Podcast is in.
What you need:

What you need:
- gPodder SVN trunk (instructions)
- gnome-bluetooth (includes gnome-obex-send)
- bluez-utils (includes hcitool) or python-bluez
- tablet-encode script from mediautils

Tuesday, January 8, 2008
Lecture Parody
Yesterday at University, our professor did a very good parody of the local show master from the Austrian version of "Who wants to be a millionaire?". Sadly, this was the last lecture this semester, but it was surely worth it :)


Sunday, December 23, 2007
Creating stopmotion movies with ffmpeg
Based on this page, I've just been able to successfully convert a bunch of photos to a MPEG4 movie:
c=0; for i in *.jpg; do mv "$i" "`printf %05d $c`.jpg"; c=$((c+1));doneThese are the settings for a bitrate of 1800 and 5 fps and the larger side of the images being scaled down to 600 pixels.
for i in *.jpg; do convert "$i" -resize 600x600 -normalize "$i"; done
ffmpeg -r 5 -b 1800 -i %05d.jpg output.mp4
Thursday, December 20, 2007
The best of three worlds
Yay! After thinking about re-installing OS X, Ubuntu and finally adding Windows XP to the mix, I played around for about 9 hours and finally was able to install Windows XP together with Mac OS X and Ubuntu 7.10, so triple-booting is now standard here! That's Windows XP for games and the usual website compatibility testing, then there is Ubuntu for all development and "default work environment" stuff and finally Mac OS X for some other useful things. All three OSes boot really quick from rEFIt, and it's much better than any virtualization can ever provide. Sadly, triple-booting is a little tricky, and especially Windows is very picky about when it decides to boot and when it doesn't (most of the time today, it didn't ;).
The trick is to get the GPT-to-MBR mapping to produce a partition table that has the Windows XP partition as last entry and be sure to let the Windows XP setup (the blue console-based one) reformat the partition - or else you will get media errors or the famous hal.dll error. Hints on how to do all this can be found here and here. You will probably not want to have swap partition, but only three "real" partitions: One for Mac OS X, one for Linux and one for Windows (in that order!). The fourth of the four partitions the MBR can have will be the EFI partition. All other partitions beyond that cannot be seen by MBR/BIOS-based OSes (like Windows). Linux and Mac OS X will "see" the GPT partition table, but I don't know if GRUB or Lilo can successfully boot off GPT partitions or if they still rely on the "bootable" partition to be accessible through the MBR.
I somehow followed the guides and did much trial-and-error, because I didn't start from scratch but wanted to keep my OS X partition and Ubuntu partition. But it is possible to get it working. If you have backups of all your data and all installation media ready (and a fast internet connection for the updates), I recommend wiping out the entire MacBook and starting from scratch by restoring Mac OS X and then following the triple-boot guide described above. And don't forget: The Windows XP partition has to be the last one in the MBR. And the partition has to be re-formatted by the windows installer to boot after the first restart. This can be accomplished by zero-ing out (using dd) the first one hundred megabytes of the Windows partition before starting the XP install.
After all, it's worth the hassle. All three mainstream operating systems on one machine is really helpful. And you won't ever go "ah, a great application, but not for me - I don't have {Windows|Mac OS X|Linux}". Yep - the best of three worlds.

The trick is to get the GPT-to-MBR mapping to produce a partition table that has the Windows XP partition as last entry and be sure to let the Windows XP setup (the blue console-based one) reformat the partition - or else you will get media errors or the famous hal.dll error. Hints on how to do all this can be found here and here. You will probably not want to have swap partition, but only three "real" partitions: One for Mac OS X, one for Linux and one for Windows (in that order!). The fourth of the four partitions the MBR can have will be the EFI partition. All other partitions beyond that cannot be seen by MBR/BIOS-based OSes (like Windows). Linux and Mac OS X will "see" the GPT partition table, but I don't know if GRUB or Lilo can successfully boot off GPT partitions or if they still rely on the "bootable" partition to be accessible through the MBR.
I somehow followed the guides and did much trial-and-error, because I didn't start from scratch but wanted to keep my OS X partition and Ubuntu partition. But it is possible to get it working. If you have backups of all your data and all installation media ready (and a fast internet connection for the updates), I recommend wiping out the entire MacBook and starting from scratch by restoring Mac OS X and then following the triple-boot guide described above. And don't forget: The Windows XP partition has to be the last one in the MBR. And the partition has to be re-formatted by the windows installer to boot after the first restart. This can be accomplished by zero-ing out (using dd) the first one hundred megabytes of the Windows partition before starting the XP install.
After all, it's worth the hassle. All three mainstream operating systems on one machine is really helpful. And you won't ever go "ah, a great application, but not for me - I don't have {Windows|Mac OS X|Linux}". Yep - the best of three worlds.

Tuesday, December 18, 2007
MacBook Ubuntu: Keypad enter opens Terminal
Here's just a short note I want to put somewhere in case I really decide to re-install Ubuntu on my MacBook and want the nice "open terminal" functionality of the keypad enter button (the button on the right side of the right apple key): Add the following line to ~/.Xmodmap:
After that, you can configure the key in System, Preferences, Keyboard Shortcuts. After logging in again (and letting Ubuntu load the Xmodmap file for you), the next terminal is just one keystroke away! Improves my productivity a lot :) The rest of setting up Ubuntu on a MacBook (including nice tweaks such as OS X-like font rendering and the correct color profile) can be found at the MacBook Ubuntu Community page.
keycode 108 = ISO_Level3_ShiftAfter that, you can configure the key in System, Preferences, Keyboard Shortcuts. After logging in again (and letting Ubuntu load the Xmodmap file for you), the next terminal is just one keystroke away! Improves my productivity a lot :) The rest of setting up Ubuntu on a MacBook (including nice tweaks such as OS X-like font rendering and the correct color profile) can be found at the MacBook Ubuntu Community page.
Monday, December 17, 2007
Bash: Power off after long-running command
Some weeks ago, I was going to go away from my machine which was running on battery power, but still had a command running (I think it was converting a MythTV recording to XviD) - anyway, I have already started the command and was now looking for a way to say "when this long-running process is finished, please shutdown the machine". Usually, you could do this using "longrunningcommandline && sudo poweroff" or similiar. However, how are you going to do this if the long-running command is already working? I had an idea and tried it straight away - it worked! You basically suspend the process (^Z) and then put it into the foreground again (fg). The "fg" command returns when the command is finished, so doing something like "fg && sudo poweroff" should accomplish the wanted thing. Of course, this can be combined with some nice script like smp to send an SMS when the command has finished.
I wanted to post this earlier, but always forgot. Today I got reminded by this website with 10 interactive shell anti-patterns - a recommended read! Shellify!
I wanted to post this earlier, but always forgot. Today I got reminded by this website with 10 interactive shell anti-patterns - a recommended read! Shellify!
Tuesday, December 11, 2007
The (re)presentational "Ähh"
"Ähhs"/"Ähms" are the German equivalent of the "umms" or "uhms" in English. Today, I held a short presentation at my University, where we did peer review by other students. Two people already counted the times I said "Ähh" (one person counted 49 - "49 Ähm's sind schon viel, nicht?!" -; another one 42 - my talking time was roughly 13 minutes). Good feedback is probably the best way to improve your presentation skills. I'm glad we did enough presentations at school, so at least the content and the presentation (apart from the numerous "Ähms") was quite okay-ish. Maybe video-taping one's own presentations would increase feedbacks and the learning effect even more :)


Saturday, December 8, 2007
Copy and paste in Linux
This week, I observed someone working on Linux struggling with copying and pasting SQL code from Emacs to a Firefox textarea. The Ctrl+C/Ctrl+V way of doing things (which I first saw on Windows, don't know who "invented" it) is nice, but once you tried the X11 way of copy and paste (using the X selection), you will never want to live without it. Being a happy user of X11 copy/paste for some years now, here's a short note for all who have not yet tried this great feature :)
To copy some text, simply select it with the mouse (no, really - just select it, no keystrokes). To paste the text you just selected, middle-click with your mouse directly where you want to paste the text - the text will be copied! As clipboard handling in Linux/X11 was (is?) a bit inconsistent, there might be some things to watch out for. For example you can only paste the selected text if the window in which you selected the text is still open.
Once you get used to that, it's really useful and you can work more productively. Nice side-effect: You can middle-click inside an open tab in firefox and have the URL in the X selection get loaded in this tab. So, to open a URL from a text file (or similiar), just select the URL, open a new tab in Firefox (or use an existing one) and middle-click inside the content area of the tab. Firefox will load the URL you just "pasted". Simple.
To copy some text, simply select it with the mouse (no, really - just select it, no keystrokes). To paste the text you just selected, middle-click with your mouse directly where you want to paste the text - the text will be copied! As clipboard handling in Linux/X11 was (is?) a bit inconsistent, there might be some things to watch out for. For example you can only paste the selected text if the window in which you selected the text is still open.
Once you get used to that, it's really useful and you can work more productively. Nice side-effect: You can middle-click inside an open tab in firefox and have the URL in the X selection get loaded in this tab. So, to open a URL from a text file (or similiar), just select the URL, open a new tab in Firefox (or use an existing one) and middle-click inside the content area of the tab. Firefox will load the URL you just "pasted". Simple.
Friday, November 30, 2007
Audio from YouTube in three steps
Needed packages: youtube-dl and mplayer. XXXX is the video ID on YouTube. You can find this out by looking at the URL of the video for which you want to get the audio.
youtube-dl http://www.youtube.com/watch?v=XXXXmplayer -dumpaudio XXXX.flvmv stream.dump XXXX.mp3
file stream.dump before renaming the file. Of course, this also works for mms:// streams with passing the mms:// URL to mplayer and using "-dumpstream" if you want the full video (or only -dumpaudio if you don't care for the video, as above).
Wednesday, November 28, 2007
The Kiss Principle: SOAP vs REST
Yesterday at university, we had a little talk about the pros and cons of SOAP. Well, not really, but SOAP was mentioned in one of the presentations, and so the professor suggested "The S stands for Simple". As he promised, it really describes the overengineered-ness of SOAP. I'm probably more the kind of REST fanboy, because it uses a widespread protocol (HTTP) and uses many of the features already present in the HTTP protocol without reinventing the wheel. What if a services moves? Do a HTTP redirect! What if there is no such service? 404! Error handling? If the error happened because of the input data, do a 4xx "client error", if not, do a 5xx "server-side error". It's simply following the Kiss principle.
Nobody likes writing wrappers, "creating" interface metadata that has to be parsed again to know how the interface looks. After all, doing sophisticated descriptions of interfaces will not automatically upgrade clients if you decide to revisit your public APIs. On the contrary, you have to re-generate (hopefully not rewrite by hand) the meta description of your API, and the client has to re-parse, re-generate or otherwise process this generalized description to finally redo their client-side code. On the other hand, when a REST-based API changes, you simply update your client-side code to work with the new API (and data structures, if they change too) and don't have to do much code generation and other "bureaucratic" code-generating nonsense.
HTTP already provides most things you expect from web services, and for really simple APIs (like the YouTube API), you can easily do "web service clients" with some http library and XML-parsing code (or not even that, but only JSON or even plaintext). In Python, I've already done this in python-youtube. The libraries I used: urllib2 and minidom from the xml.dom package - both included in the Python Standard Library. It surely is easier maintainable than, for example, with Python Web Services.
What I really want to say is that if you're doing public APIs, why not simply do it with REST instead of SOAP/Web Services (that is, if you're the provider of these services - you probably can't choose when you are interfacing with web services/APIs written by someone else)?
Nobody likes writing wrappers, "creating" interface metadata that has to be parsed again to know how the interface looks. After all, doing sophisticated descriptions of interfaces will not automatically upgrade clients if you decide to revisit your public APIs. On the contrary, you have to re-generate (hopefully not rewrite by hand) the meta description of your API, and the client has to re-parse, re-generate or otherwise process this generalized description to finally redo their client-side code. On the other hand, when a REST-based API changes, you simply update your client-side code to work with the new API (and data structures, if they change too) and don't have to do much code generation and other "bureaucratic" code-generating nonsense.
HTTP already provides most things you expect from web services, and for really simple APIs (like the YouTube API), you can easily do "web service clients" with some http library and XML-parsing code (or not even that, but only JSON or even plaintext). In Python, I've already done this in python-youtube. The libraries I used: urllib2 and minidom from the xml.dom package - both included in the Python Standard Library. It surely is easier maintainable than, for example, with Python Web Services.
What I really want to say is that if you're doing public APIs, why not simply do it with REST instead of SOAP/Web Services (that is, if you're the provider of these services - you probably can't choose when you are interfacing with web services/APIs written by someone else)?
Wednesday, November 21, 2007
News from the Windows world
For compiling Tennix, doing some Windows-only work, testing website in IE6 and other tasks that require Win32, I still have a Windows 2000 installation that I use and update occassionally.
The last Sun Java update was a very pleasant surprise, as the update box did advertise OpenOffice.org (the MS Office competitor that has been bootstrapped and is now sponsored by Sun Microsystems). So, here's Sun using its leading(?) position in the Java JVM market to push another product that directly competes with Microsoft products.
I, for one, welcome this, as OOo has the advantage of being open source, and free as in beer. Did I mention you can easily export your documents into PDFs in OOo without the need for 3rd party software? I have yet to see this feature in Microsoft Office, but I think the last MS Office version I used was Office 2003 or so and they might have included that feature since then. Probably the most important reason for OpenOffice.org is the open, patent-free file format. Anyway, here's a screenshot of the Java Updater:

Another screenshot I want to share with you is related to wavbreaker. No, it doesn't currently work (well) on Win32, and there are still some rough edges (forking and killing processes is quite different on Unix compared to Windows), and no output (as wavbreaker currently only supports OSS and ALSA, although I'm working on getting PulseAudio support into it, so we could have a chance of using wavbreaker on Windows via the Windows port of PulseAudio). There are a lot dependencies to resolve (GTK+2.0 and all its dependencies) and drag into your msys/mingw installation before you can start, so I won't go about describing the whole procedure - after all, wavbreaker in it's current state isn't really usable on Windows (only display and cutting works, no audio playback). Anyway, here's the obligatory proof-of-concept screenshot:

The last Sun Java update was a very pleasant surprise, as the update box did advertise OpenOffice.org (the MS Office competitor that has been bootstrapped and is now sponsored by Sun Microsystems). So, here's Sun using its leading(?) position in the Java JVM market to push another product that directly competes with Microsoft products.
I, for one, welcome this, as OOo has the advantage of being open source, and free as in beer. Did I mention you can easily export your documents into PDFs in OOo without the need for 3rd party software? I have yet to see this feature in Microsoft Office, but I think the last MS Office version I used was Office 2003 or so and they might have included that feature since then. Probably the most important reason for OpenOffice.org is the open, patent-free file format. Anyway, here's a screenshot of the Java Updater:

Another screenshot I want to share with you is related to wavbreaker. No, it doesn't currently work (well) on Win32, and there are still some rough edges (forking and killing processes is quite different on Unix compared to Windows), and no output (as wavbreaker currently only supports OSS and ALSA, although I'm working on getting PulseAudio support into it, so we could have a chance of using wavbreaker on Windows via the Windows port of PulseAudio). There are a lot dependencies to resolve (GTK+2.0 and all its dependencies) and drag into your msys/mingw installation before you can start, so I won't go about describing the whole procedure - after all, wavbreaker in it's current state isn't really usable on Windows (only display and cutting works, no audio playback). Anyway, here's the obligatory proof-of-concept screenshot:

Monday, November 19, 2007
Disabling startup sound/chime on the MacBook
Today at university, a fellow student asked me about how I disabled the startup chime/sound that the MacBook makes when it is powered on from cold state. I remembered I applied some setting after a suggestion on the mactel-linux-users mailing list, but I didn't remember exactly how I did it. Just in case, I need to repeat this procedure, and to tell him what worked for me, I started looking for the corresponding post. Here it is: how to silence apple startup chime.
Good thing that OS X is based on BSD, and therefore very unix-y, we can simply edit the local shutdown script (/etc/rc.shutdown.local) and append the following line:
Good thing that OS X is based on BSD, and therefore very unix-y, we can simply edit the local shutdown script (/etc/rc.shutdown.local) and append the following line:
/usr/sbin/nvram SystemAudioVolume=%80This will set the volume in nvram to zero and effectively disable the startup chime, so you won't be annoyed by the startup chime when you forgot to mute the OS X audio volume before shutdown. The good thing with this method is that you don't need to install nasty third-party software, and that it still preserves the volume settings inside Mac OS X and (of course) in Linux, thanks to alsactl's restore functionality.
Friday, November 16, 2007
Patch for Jilorio
Alberto Ruiz has posted a nice little utility on his blog in July. I've tried this script several weeks ago, and found some problems (deprecated gtk calls, about box annoyances, default icon) that I quickly fixed in my local git clone. I haven't used Jilorio since, but the patch still works, so if there are still Jilorio users out there, you might want to start from the upstream git repository and apply my patch on top of this codebase.
Thursday, November 8, 2007
Episode selector dialog for gPodder
 Today after University, I decided to hack a feature into gPodder that I have thought about for a while - the episode selector dialog. It should be used in several user interaction situations where a simple binary question is not specific enough ("delete old episodes?" vs "which of these old episodes do you really want to remove?"). So I set out implementing this neat little feature and when I looked at the watch and decided that I had to leave for math classes, most of the episodes selector has been implemented, with quite some fancy features and options. I used the last two hours to look through the my working copy diff to fix some obvious omissions, but as of now, the code of the new episode selector is already in SVN. I've attached some screenshots so you can see how it looks.
Today after University, I decided to hack a feature into gPodder that I have thought about for a while - the episode selector dialog. It should be used in several user interaction situations where a simple binary question is not specific enough ("delete old episodes?" vs "which of these old episodes do you really want to remove?"). So I set out implementing this neat little feature and when I looked at the watch and decided that I had to leave for math classes, most of the episodes selector has been implemented, with quite some fancy features and options. I used the last two hours to look through the my working copy diff to fix some obvious omissions, but as of now, the code of the new episode selector is already in SVN. I've attached some screenshots so you can see how it looks. Thanks to lambda expressions, PyGTK coolness and getattr, i.e. accessing attributes by name, this dialog is now quite customizable and the code is still readable and (compared to what other languages would have yielded), small. If you are using gPodder, be sure to check out the current SVN trunk head.
Thanks to lambda expressions, PyGTK coolness and getattr, i.e. accessing attributes by name, this dialog is now quite customizable and the code is still readable and (compared to what other languages would have yielded), small. If you are using gPodder, be sure to check out the current SVN trunk head. One feature I used several times was enumerate() - you give an iterable as parameter, and get a generator that yields tuples with two elements - a zero-based index and the values you would normally get from the iterables directly. So, instead of writing code like this:
One feature I used several times was enumerate() - you give an iterable as parameter, and get a generator that yields tuples with two elements - a zero-based index and the values you would normally get from the iterables directly. So, instead of writing code like this:index = 0you can simply write
for item in items:
print 'item %d is %s' % ( index, item )
index += 1
for index, item in enumerate( items):which isn't only nicer, but you save two lines and the code is IMHO more readable (you instantly recognize "index" as being related to the for loop in the second code snippet).
print 'item %d is %s' % ( index, item )
Saturday, November 3, 2007
Massive mail and web hosting in Debian
I migrated some web and mail services from a custom Linux distro with Apache2 and Cyrus-imapd to Apache2.2 and Dovecot (imapd + pop3d). Because there are lots of Domains, Subdomains and mail aliases, I wanted to unify as much of the configuration as possible to make maintaining the services easier.
Massive name-based virtual hosting with Apache2
The document "Dynamically configured mass virtual hosting" in the Apache HTTP Server documentation describes how to set up dynamic virtual hosting. I needed name-based virtual hosting, so I created a file "/etc/apache2/conf.d/vhosting" with the following contents:
UseCanonicalName Off
VirtualDocumentRoot /srv/www/%-2.0+.%-1/%-3+/
AllowOverride all
Options +Indexes
This will automatically map subdomain.example.com to /srv/www/example.com/subdomain/. You can then even think of more sophisticated usage, such as placing a .htaccess file with a Redirect directive in /srv/www/redirected-domain.tld/.
Migrating Cyrus mails to Dovecot Maildirs
Fazal Majid has written a Python script that can be found in this blog post. You might have to modify a bit, but apart from that, it serves the purpose well. After you have converted the (nonstandard) Cyrus mail dir to the standard Maildir(++) format, the Maildirs can be used with the Dovecot mail server. Of course, you should configure exim4 to deliver new mail into "Maildir" in the users' home directories.
Massive E-Mail virtual hosting with Exim4
Another problem that arose was multiple domains and different users for E-Mail. Thankfully, Aron Håkanson has had the same problem and written the article Virtual domains with Exim 4, in which he describes how to set up massive E-Mail virtual hosting on Debian with Exim4. This makes maintaining a plaintext list of mail alias mappings for virtual servers and a list of domains for which to handle mails very easy and keeps the list maintainer happy.
Massive name-based virtual hosting with Apache2
The document "Dynamically configured mass virtual hosting" in the Apache HTTP Server documentation describes how to set up dynamic virtual hosting. I needed name-based virtual hosting, so I created a file "/etc/apache2/conf.d/vhosting" with the following contents:
UseCanonicalName Off
VirtualDocumentRoot /srv/www/%-2.0+.%-1/%-3+/
AllowOverride all
Options +Indexes
This will automatically map subdomain.example.com to /srv/www/example.com/subdomain/. You can then even think of more sophisticated usage, such as placing a .htaccess file with a Redirect directive in /srv/www/redirected-domain.tld/.
Migrating Cyrus mails to Dovecot Maildirs
Fazal Majid has written a Python script that can be found in this blog post. You might have to modify a bit, but apart from that, it serves the purpose well. After you have converted the (nonstandard) Cyrus mail dir to the standard Maildir(++) format, the Maildirs can be used with the Dovecot mail server. Of course, you should configure exim4 to deliver new mail into "Maildir" in the users' home directories.
Massive E-Mail virtual hosting with Exim4
Another problem that arose was multiple domains and different users for E-Mail. Thankfully, Aron Håkanson has had the same problem and written the article Virtual domains with Exim 4, in which he describes how to set up massive E-Mail virtual hosting on Debian with Exim4. This makes maintaining a plaintext list of mail alias mappings for virtual servers and a list of domains for which to handle mails very easy and keeps the list maintainer happy.
Sunday, October 28, 2007
MacBook Linux Live CDs
Last week, Ubuntu 7.10 came out, and so I thought I might give it a try on my August 2006 MacBook (non-Pro). Today, I tried out the Fedora 8 Test 3 Live CD - the same thing Ubuntu provides with its "Live Desktop" CD (boot system from CD, try it out, if you like it, you can install it to your hard disk).
Guess what? Ubuntu 7.10 crashed with a distorted screen, while Fedora 8 booted happily with a very nice boot splash that even had mouse support. It also seems like Fedora 8 is more advanced, technology-wise with its PulseAudio (very cool) and NetworkManager 0.7, although I think the version of NetworkManager in Fedora 8 Test 3 isn't the NM version that will be put in F8.
Anyway, testing these "new" releases of the flashy, user-friendly Linux distros showed me some really neat things (PulseAudio is what I want to have installed soon :), but I'm perfectly fine with my Debian testing/unstable system, which is cool, dpkg-based, fresh and already set up to my taste :) I also like the way Debian keeps most things "vanilla" and doesn't try to brand the whole Desktop with logos of the distro, and a special GTK+ and icon theme, opposed to the fully-branded Fedora and Ubuntu distros, although I'd like to see the new Fedora GTK, Metacity and GDM themes available as a package in Debian, because the look is quite nice.
Thursday, October 25, 2007
BSD-licensed Face Recognition Software
Curious as I am, I just tried to find some free software face recognition source code around the web. Among the two projects I found (one being very crude, unmaintained old C++ code), the Machine Perception Toolbox was the most interesting and advanced library, licensed under a BSD-style license.
On Debian, you have to install the "bjam" package, modify the "boost-build/user-config.jam" file (put "using darwin;" in comments and comment-out "using gcc;"). Then, cd into "Apps/unix/mpisearch" and simply run "bjam" (it's a make-like thingamoob). The resulting binary can be found in "bin/gcc/debug/optimization-speed/mpisearch", and you can simply call it with an image file as argument which will be processed and the result displayed on your X server. You might have to install the Magick++ development packages if compilation fails and fix some namespace problems in the C++ code (quite obvious after Googling for the error message).
The source code for the "mpisearch" is in "Apps/unix/mpisearch/main.cc", and it's very easy to understand, so you can modify the code to fit your needs (e.g. make it output the coordinates of the "face" rectangles and then parse the command's output in your scripts, etc..). Maybe that would be an interesting feature to add to photo websites :)
On Debian, you have to install the "bjam" package, modify the "boost-build/user-config.jam" file (put "using darwin;" in comments and comment-out "using gcc;"). Then, cd into "Apps/unix/mpisearch" and simply run "bjam" (it's a make-like thingamoob). The resulting binary can be found in "bin/gcc/debug/optimization-speed/mpisearch", and you can simply call it with an image file as argument which will be processed and the result displayed on your X server. You might have to install the Magick++ development packages if compilation fails and fix some namespace problems in the C++ code (quite obvious after Googling for the error message).
The source code for the "mpisearch" is in "Apps/unix/mpisearch/main.cc", and it's very easy to understand, so you can modify the code to fit your needs (e.g. make it output the coordinates of the "face" rectangles and then parse the command's output in your scripts, etc..). Maybe that would be an interesting feature to add to photo websites :)
Saturday, October 6, 2007
Fixing Macbook problems
Today, I've set out to fix some problems and annoyances that I had with my MacBook (August 2006) for several months:
I figured some of these problems were related to having obsolete/old kernel command line parameters that were needed for older 2.6 kernels to get things working, but are not needed for recent kernels. I'm currently using Debian's stock 2.6.22-2-686 kernel. The "append=" line in my /etc/lilo.conf for the kernel was "noapic acpi=force irqpoll resume=/dev/sda4". Removing the "noapic" option fixed the "NMI appears to be stuck" problem. Additionally, removing the "irqpoll" option fixed the CD-ROM drive problem ("drive appears confused"). Now, I can boot newer (2.6.22) kernels and have a working CD-ROM drive again (previously, the CD-ROM drive spontaneously "detected" an inserted Audio CD when there really was no CD inserted).
Compiz Fusion/Beryl and the intel driver bug
I've been running Compiz Fusion (and previously Beryl) and it worked great, except that when VT switching to the text console, the whole Macbook locked up sometimes. This bug is described in bug #127101 on Launchpad.net. So, I have now disabled the whole Compiz Fusion stuff and things seem to be working fine now, I have not yet had a random lock-up and garbled screen since. Sure, Metacity is not as nice as Compiz Fusion, and some Compiz features are really useful (Scale plug-in and Expo plug-in among some others), but it's better to have reliable shutdown than some Desktop bling-bling. With this text VT switch bug fixed, I've tried Suspend-to-RAM, which also seems to work okay-ish now. That would make Linux (Debian) awesome on that Apple MacBook :)
- Suspend-to-RAM not working
- CD-ROM drive works unreliably (hda: drive appears confused)
- Newer kernels don't boot ("NMI appears to be stuck (0->0)!")
- Random lock-ups when VT switching from Xorg to text console
I figured some of these problems were related to having obsolete/old kernel command line parameters that were needed for older 2.6 kernels to get things working, but are not needed for recent kernels. I'm currently using Debian's stock 2.6.22-2-686 kernel. The "append=" line in my /etc/lilo.conf for the kernel was "noapic acpi=force irqpoll resume=/dev/sda4". Removing the "noapic" option fixed the "NMI appears to be stuck" problem. Additionally, removing the "irqpoll" option fixed the CD-ROM drive problem ("drive appears confused"). Now, I can boot newer (2.6.22) kernels and have a working CD-ROM drive again (previously, the CD-ROM drive spontaneously "detected" an inserted Audio CD when there really was no CD inserted).
Compiz Fusion/Beryl and the intel driver bug
I've been running Compiz Fusion (and previously Beryl) and it worked great, except that when VT switching to the text console, the whole Macbook locked up sometimes. This bug is described in bug #127101 on Launchpad.net. So, I have now disabled the whole Compiz Fusion stuff and things seem to be working fine now, I have not yet had a random lock-up and garbled screen since. Sure, Metacity is not as nice as Compiz Fusion, and some Compiz features are really useful (Scale plug-in and Expo plug-in among some others), but it's better to have reliable shutdown than some Desktop bling-bling. With this text VT switch bug fixed, I've tried Suspend-to-RAM, which also seems to work okay-ish now. That would make Linux (Debian) awesome on that Apple MacBook :)
Thursday, October 4, 2007
Hauppauge WinTV Nova-T Stick under Linux
I just got myself a Hauppauge WinTV Nova-T Stick (USB) and tried to get it working in Linux. With a bit of fiddling, I've got everything working, and also found an application to extract EPG info that can be displayed with OnTV.
First of all, you need to get the correct firmware. The file you need should be in the "dmesg" output after plugging in the stick. For me, the firmware file I needed was dvb-usb-dib0700-01.fw, so I googled around for it, found it and placed it in /lib/firmware/. After re-connecting the stick, the "dmesg" output should tell you that the firmware has been loaded. To get a working list of channels, I used w_scan with the "-X" parameter to generate a channels.conf.
Then, I downloaded xine (actually, I installed xine-ui in Debian) and placed the previously-generated channels.conf into ~/.xine/. This should already make things working: Start up xine, select "DVB" and wait for the channel to load. I had to change my window manager from Compiz to Metacity to prevent some errors related to the video stuff. With Metacity as window manager and xine, I get very good and performant video.
For EPG/XMLTV, I checked out the current Subversion trunk head of tv_grab_dvb. Compile it. To get the EPG data, you can't just simply tv_grab_dvb (or you can, but you would have to tune in somehow, which I didn't figure out). I solved this problem by simply running xine and watching TV, which tunes in into the right station, then running "tv_grab_dvb -e utf-8 -t 2 > ~/tv-guide.xml". This should result in a nice XMLTV file that can be parsed by other applications to give you EPG info. You can load this file into OnTV and have an EPG. To get OnTV for Debian, I downloaded the Ubuntu source package for "ontv" and compiled it on Debian. Then, add "OnTV" to your gnome-panel and configure it with the XMLTV you generated above. Then, select the TV channels to monitor and click on the TV icon. You should see the list of current programs.
So, DVB-T on Linux works fine with the Hauppauge WinTV Nova-T Stick. Neat!
Update: The stick was only for testing compatibility on Linux, I don't use it anymore. Please see the Linux TV websites for more information.
First of all, you need to get the correct firmware. The file you need should be in the "dmesg" output after plugging in the stick. For me, the firmware file I needed was dvb-usb-dib0700-01.fw, so I googled around for it, found it and placed it in /lib/firmware/. After re-connecting the stick, the "dmesg" output should tell you that the firmware has been loaded. To get a working list of channels, I used w_scan with the "-X" parameter to generate a channels.conf.
Then, I downloaded xine (actually, I installed xine-ui in Debian) and placed the previously-generated channels.conf into ~/.xine/. This should already make things working: Start up xine, select "DVB" and wait for the channel to load. I had to change my window manager from Compiz to Metacity to prevent some errors related to the video stuff. With Metacity as window manager and xine, I get very good and performant video.
For EPG/XMLTV, I checked out the current Subversion trunk head of tv_grab_dvb. Compile it. To get the EPG data, you can't just simply tv_grab_dvb (or you can, but you would have to tune in somehow, which I didn't figure out). I solved this problem by simply running xine and watching TV, which tunes in into the right station, then running "tv_grab_dvb -e utf-8 -t 2 > ~/tv-guide.xml". This should result in a nice XMLTV file that can be parsed by other applications to give you EPG info. You can load this file into OnTV and have an EPG. To get OnTV for Debian, I downloaded the Ubuntu source package for "ontv" and compiled it on Debian. Then, add "OnTV" to your gnome-panel and configure it with the XMLTV you generated above. Then, select the TV channels to monitor and click on the TV icon. You should see the list of current programs.
So, DVB-T on Linux works fine with the Hauppauge WinTV Nova-T Stick. Neat!
Update: The stick was only for testing compatibility on Linux, I don't use it anymore. Please see the Linux TV websites for more information.
Thursday, September 27, 2007
Stupid Notification E-Mails
Web-based services are great for various things. For example, I'm a user of the Game Trading Zone for trading old games, a user of YouTube for publishing short video clips and just today I've signed up on StudiVZ, a social networking site for students.
Of course, I'm not going to sign in to every service every day just to check if there are new messages or something that needs my attention. That's what e-mail notifications are here for. The best and most useful e-mail notifications I get are the ones from the Game Trading Zone: Another user sends you an offer and in the e-mail you get a complete description of the offer (what's offered + details of items, custom message, shipping and other settings) and a link to go directly to the offer site. A dream! As soon as I open the e-mail, I know all about the offer and can decide what to do.
Not so with the two bad examples which upset me so much today that I started writing what you read here. I've often got notifications from YouTube, which sends out a notification e-mail whenever someone posts a comment to a video I've uploaded. BUT the actual comment isn't in the e-mail, for that I have to open the YouTube website. How stupid is that? If they just sent the comment in the mail, I could quickly read it and decide if I have to reply, delete the (spam) comment or just read it and forget about it. Instead I have to open that YouTube page. The same stupid thing is present in StudiVZ, so they also just tell you that there is something new, but don't tell you what it is.
So, instead of a simple "read - react" cycle, I have to do a "click link - wait for browser to open - wait for page to load - search for the information in question - read - react", which is so time consuming and stupid that I really had to write this post (which, of course, takes probably as much time writing as reading one month's worth of stupid notification mails, but anyway..).
If you provide some web service that does e-mail notifications, please include useful, readable and compact information about the change/comment/whatever that you want to get through to your user. Just sending links as in "something's new, click the link to find out what it is" is just plain stupid :(
Of course, I'm not going to sign in to every service every day just to check if there are new messages or something that needs my attention. That's what e-mail notifications are here for. The best and most useful e-mail notifications I get are the ones from the Game Trading Zone: Another user sends you an offer and in the e-mail you get a complete description of the offer (what's offered + details of items, custom message, shipping and other settings) and a link to go directly to the offer site. A dream! As soon as I open the e-mail, I know all about the offer and can decide what to do.
Not so with the two bad examples which upset me so much today that I started writing what you read here. I've often got notifications from YouTube, which sends out a notification e-mail whenever someone posts a comment to a video I've uploaded. BUT the actual comment isn't in the e-mail, for that I have to open the YouTube website. How stupid is that? If they just sent the comment in the mail, I could quickly read it and decide if I have to reply, delete the (spam) comment or just read it and forget about it. Instead I have to open that YouTube page. The same stupid thing is present in StudiVZ, so they also just tell you that there is something new, but don't tell you what it is.
So, instead of a simple "read - react" cycle, I have to do a "click link - wait for browser to open - wait for page to load - search for the information in question - read - react", which is so time consuming and stupid that I really had to write this post (which, of course, takes probably as much time writing as reading one month's worth of stupid notification mails, but anyway..).
If you provide some web service that does e-mail notifications, please include useful, readable and compact information about the change/comment/whatever that you want to get through to your user. Just sending links as in "something's new, click the link to find out what it is" is just plain stupid :(
Wednesday, September 26, 2007
PyGTK applications on Windows
One advantage that you automatically gain when writing Python programs is that they are portable to several other mainstream operating systems (although there are some problems with specific extensions, etc..).
So, after releasing gPodder 0.10.0, which has now only one strict dependency on a pure Python module (feedparser), I wanted to try out if I could get gPodder running on Windows (I have tried it once before, but back then I was spawning a wget process to do the actual downloading, which was kind of awkward on the Windows platform).
What you need to get this working is Alberto Ruiz' All-in-one PyGTK Win32 installer and a check-out of the current SVN trunk head of gPodder. To check out a working copy from a Subversion repository on Win32, you can use TortoiseSVN.
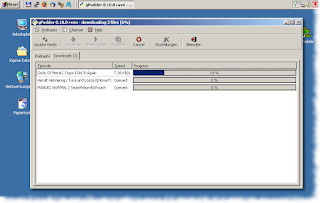
I've found some divide-by-zero errors that I didn't see happening on Linux, so I could quickly fix them in our Subversion repository. I also got rid of some old symlinking code that I didn't use anymore, because symlinks on Windows isn't really possible (except for Vista maybe). Other than that, there were just some minor problems with my code being Unix/X11-specific, for example I'm checking for the $DISPLAY variable in the main script, which isn't needed on Win32.
There were other minor annoyances which I haven't dealt with yet, but which don't interfere with the basic functionality of gPodder:
So, after releasing gPodder 0.10.0, which has now only one strict dependency on a pure Python module (feedparser), I wanted to try out if I could get gPodder running on Windows (I have tried it once before, but back then I was spawning a wget process to do the actual downloading, which was kind of awkward on the Windows platform).
What you need to get this working is Alberto Ruiz' All-in-one PyGTK Win32 installer and a check-out of the current SVN trunk head of gPodder. To check out a working copy from a Subversion repository on Win32, you can use TortoiseSVN.

I've found some divide-by-zero errors that I didn't see happening on Linux, so I could quickly fix them in our Subversion repository. I also got rid of some old symlinking code that I didn't use anymore, because symlinks on Windows isn't really possible (except for Vista maybe). Other than that, there were just some minor problems with my code being Unix/X11-specific, for example I'm checking for the $DISPLAY variable in the main script, which isn't needed on Win32.
There were other minor annoyances which I haven't dealt with yet, but which don't interfere with the basic functionality of gPodder:
- Running .mp3 or .avi files with the preferred media player (how do I do that on Win32?)
- Getting a GTK Icon Theme into my GTK installation, so all icons in gPodder display properly
- Removing the GUI for iPod synchronization (or get libgpod + Python bindings working on Win32)
- Testing, testing testing :)
Thursday, September 13, 2007
X11 idle time and focused window in Python
For my Evolution New Mail Notification script, I wanted to make the notification popups not enabled when I'm already working within evolution (e.g. the Evolution window is focused) and I also didn't want to play sounds when I'm working on the computer, because I will see the visual notification, anyway (e.g. the X11 idle time is less than some specified timeout).
To accomplish that, I had to write a bit of Python code for two simple tasks:
Window Name and Class for the focused window
To accomplish that, I had to write a bit of Python code for two simple tasks:
- Get the window name and/or class of the currently focused window
- Get the idle time of the X11 session, e.g. the time since the last input event
Window Name and Class for the focused window
import Xlib.displayX11 Idle Time using the XScreenSaver extension
display = Xlib.display.Display()
focus = display.get_input_focus()
print "WM Class: %s" % ( focus.focus.get_wm_class(), )
print "WM Name: %s" % ( focus.focus.get_wm_name(), )
import ctypesIf you're interested in a real-world example usage of this code, feel free to check out my evolution-newmail.py new mail notification script that works with Evolution over D-BUS.
import os
class XScreenSaverInfo( ctypes.Structure):
""" typedef struct { ... } XScreenSaverInfo; """
_fields_ = [('window', ctypes.c_ulong), # screen saver window
('state', ctypes.c_int), # off,on,disabled
('kind', ctypes.c_int), # blanked,internal,external
('since', ctypes.c_ulong), # milliseconds
('idle', ctypes.c_ulong), # milliseconds
('event_mask', ctypes.c_ulong)] # events
xlib = ctypes.cdll.LoadLibrary( 'libX11.so')
dpy = xlib.XOpenDisplay( os.environ['DISPLAY'])
root = xlib.XDefaultRootWindow( dpy)
xss = ctypes.cdll.LoadLibrary( 'libXss.so')
xss.XScreenSaverAllocInfo.restype = ctypes.POINTER(XScreenSaverInfo)
xss_info = xss.XScreenSaverAllocInfo()
xss.XScreenSaverQueryInfo( dpy, root, xss_info)
print "Idle time in milliseconds: %d" % ( xss_info.contents.idle, )
Wednesday, September 12, 2007
Downloading in Python?
Currently, I'm using a rather ugly way of downloading files in my Python application by executing a "wget" process and extracting progress and speed information from wget's stderr output. Of course, this is ugly and it depends on many factors (did you know RedHat/Fedora's wget has a different output format?
Ideally, I'd like to replace the current code with something completely Python-ish (using urllib2?). The ideal solution would:
Ideally, I'd like to replace the current code with something completely Python-ish (using urllib2?). The ideal solution would:
- Be completely written in Python
- Download URLs to specified local file names
- Be threaded (or runnable in threads)
- Report current speed (e.g. 40kb/s) and progress (40% done)
- Cancelling in-progress downloads should be possible
- Optionally provide the "estimated time left"
- Handle URL redirections, HTTP authentication, etc..
Sunday, August 26, 2007
Simplifying gPodder website navigation
Today, I've updated the gPodder website (navigation) to be more usable and easier to navigate. I've added stock Gnome icons and moved some previously top-level items into the "documentation" menu item or elsewhere. This makes navigation easier and the design also looks a bit more modern, have a look:

You can find the new gPodder website at the usual location: http://gpodder.berlios.de/. Oh, and by the way: I've just released a new version (0.9.5) today, so if you're using gPodder, be sure to check out the new release.

You can find the new gPodder website at the usual location: http://gpodder.berlios.de/. Oh, and by the way: I've just released a new version (0.9.5) today, so if you're using gPodder, be sure to check out the new release.
Wednesday, August 22, 2007
Minimalistic Evolution phonebook extractor
If you're using Evolution as your E-Mail client and contact management application, and you like Python, here is a small snippet that allows you to dump out all phone numbers of your contacts to the console. Of course, with this code as a guide, you can produce even more useful applications ;)
What you need: Evolution, pygobject, evolution-python, Python (2.4 or higher) and some contacts in your contact list
What you need: Evolution, pygobject, evolution-python, Python (2.4 or higher) and some contacts in your contact list
#!/usr/bin/python
import evolution
import gobject
book = evolution.open_addressbook('default')
props = gobject.list_properties( evolution.EContact)
pp = [ p.name for p in props if 'phone' in p.name ]
for contact in book.get_all_contacts():
gp = contact.get_property
name = gp('file-as')
numbers = ', '.join( [ gp(p) for p in pp if gp(p) ])
if numbers:
print ': '.join( [ name, numbers ])
Thursday, August 9, 2007
Threading and Locks
This week, I've been bitten by a dead-lock bug in my website's code twice already, and I've decided to fix it, and to write about it, as it seems like a common problem when starting with threading. To use a thread lock in Python, the threading module provides a
The problem is, that if
In the Python Cookbook, there is also a decorator version of this, so when using Python 2.4 and above, and you like using decorators, try the sychronized decorator and "decorate" your function:
Threads in Python are cool, and if you're careful using them, you can make your application run faster without affecting the stability or flow of your application. A lesson I learned last weekend when a bug with locking resulting in my WSGI app dead-locking and the website unreacheable.
Lock class that has two methods: acquire() and release(). Usually, one would think that thread-unsafe code should be "protected" by the lock like this ("lo" is a Lock variable):def do_something():
lo.acquire()
do_threadunsafe_operation()
lo.release()
The problem is, that if
do_threadunsafe_operation() raises an exception, the lock will not be released, and therefore, all subsequent calls to do_something() will lock forever. You have to put the code in a try..finally block to make sure the lock gets released when the function ends:def do_something():
lo.acquire()
try:
do_threadunsafe_operation()
finally:
lo.release()
In the Python Cookbook, there is also a decorator version of this, so when using Python 2.4 and above, and you like using decorators, try the sychronized decorator and "decorate" your function:
@synchronized(lo)
def do_threadunsafe_operation():
pass
Threads in Python are cool, and if you're careful using them, you can make your application run faster without affecting the stability or flow of your application. A lesson I learned last weekend when a bug with locking resulting in my WSGI app dead-locking and the website unreacheable.
Tuesday, August 7, 2007
Python Paste Easter Egg.
While looking for documentation on Paste's HTTP server module, I have found something funny:
from paste import ponyThe module documentation for paste.pony can be found here, and the corresponding highlighted source file here.
print pony.PONY.decode('base64').decode('zlib')
print pony.UNICORN.decode('base64').decode('zlib')
Sunday, August 5, 2007
Python Import Hell
Coming from a Java background to Python about two years ago, I suppose I confused Python packages and modules a bit (compare Java's packages and classes - it's a different thing!). Anyway, gPodder's current module and package structure is a bit uncoordinated, partly because I started out with the module layout early in my Python carreer and partly because I sometimes added classes where they shouldn't be placed, resulting in circular imports. I somehow managed to fix all import errors and it runs for quite a while with that layout now.
After Pierre-Luc Beaudoin informed me that his Sofa Media Center now uses gPodder as its podcast client/backend, and after looking at Pierre-Luc's code, I thought it would be good to provide some kind of gPodder API for other developers to build upon the gPodder functionality. This way, gPodder would be a modular app with a GUI, but it could also function as simple podcast client library (if needed).
So, yesterday, I started to restructure the gPodder package/module layout a bit. While doing this, I had some problems with circular imports. The problem was that I had a "gpodder" module in the "gpodder" package, and Python 2.4's "import" statement first searches the current package and then the "global" package/module path. I read about Python's built-in Package support that is available since Python 1.5. Great! But it already mentions that there could be problems with relative imports. Another article entited Importing Python Modules then explained the partly confusing import hell of Python. The article says one should "always use import X" (except for some special cases).
Circular imports can often easily be avoided by placing depended-on code in seperate modules. It's also good to see that this problem is partly solved by PEP 328, which is (optionally) available starting with python 2.5, throws a warning and 2.6 and will be the default in Python 2.7: Absolute imports. This way, naming a package-local module like a top-level package will not result in confusion. One can either use "import X" to do an absolute import or do "from . import X" to do a relative import. Currently (Python 2.4), "import X" will prefer the local module over a global package/module with the same name. Confusing, isn't it?
After Pierre-Luc Beaudoin informed me that his Sofa Media Center now uses gPodder as its podcast client/backend, and after looking at Pierre-Luc's code, I thought it would be good to provide some kind of gPodder API for other developers to build upon the gPodder functionality. This way, gPodder would be a modular app with a GUI, but it could also function as simple podcast client library (if needed).
So, yesterday, I started to restructure the gPodder package/module layout a bit. While doing this, I had some problems with circular imports. The problem was that I had a "gpodder" module in the "gpodder" package, and Python 2.4's "import" statement first searches the current package and then the "global" package/module path. I read about Python's built-in Package support that is available since Python 1.5. Great! But it already mentions that there could be problems with relative imports. Another article entited Importing Python Modules then explained the partly confusing import hell of Python. The article says one should "always use import X" (except for some special cases).
Circular imports can often easily be avoided by placing depended-on code in seperate modules. It's also good to see that this problem is partly solved by PEP 328, which is (optionally) available starting with python 2.5, throws a warning and 2.6 and will be the default in Python 2.7: Absolute imports. This way, naming a package-local module like a top-level package will not result in confusion. One can either use "import X" to do an absolute import or do "from . import X" to do a relative import. Currently (Python 2.4), "import X" will prefer the local module over a global package/module with the same name. Confusing, isn't it?
Sunday, July 29, 2007
WSGI is my homeboy!
A sunday afternoon is always good for a surprising journey on the Internet. Today, I was looking into WSGI, after reading some Python-related websites. Combined with the fact that I was really upset about the new perli.net Codebase being slow and unstable, I decided to have a look at WSGI to fix my problems with multi-process mod_python and Python instances. I found the great tutorial "A Do-It-Yourself framework" by Ian Bicking.
I was quickly able to hack together a small WSGI-capable test application. Gladly, I have designed the perli.net Codebase so that the underlying (mod_python) is abstracted by a "Request" class I've written. This was a really good design decision, as I was able to easily adopt that class to work with WSGI instead of mod_python without having to look through the whole codebase. One the "Request" object (and some associated handling classes and functions) were updated to WSGI, I was able to start the test server (Paste's httpserver) and had the codebase running on WSGI! Great!
There were still some problems with SQLAlchemy, so after looking around on the web and asking on IRC, I did two things: Migrate from MyISAM to InnoDB (transaction-based SQL engine) and created a threading.Lock() object in the database access object and wrapped all database access calls between lock.acquire() and lock.release() calls. Now, SQLAlchemy is running much better and stable than before. Not only because of the changes I did, but also because the WSGI makes it possible to run one process with multiple threads (instead of multiple processes, where SQLAlchemy can't share objects between page requests).
To test my changes and to see if the server will stay stable with many concurrent requests, I installed Siege and pointed it at my local webserver. I was able to fix some miscellaneous bugs that cropped up while testing with Siege, and also had statistics on how fast a page would be generated. On my 2GHz (2GB RAM) MacBook, the first photo overview page loaded for about 6 to 15 seconds (HTML only), depending on load. This was way too long, so I thought about implementing some kind of cache.
I'm now caching certain pager data that can be cached and doesn't depend on users being logged in or not. This reduces the page load time to about 0.3 seconds (HTML only, again), so perli.net should be a bit faster on certain pages. A good space-time tradeoff, I think :)
I was quickly able to hack together a small WSGI-capable test application. Gladly, I have designed the perli.net Codebase so that the underlying (mod_python) is abstracted by a "Request" class I've written. This was a really good design decision, as I was able to easily adopt that class to work with WSGI instead of mod_python without having to look through the whole codebase. One the "Request" object (and some associated handling classes and functions) were updated to WSGI, I was able to start the test server (Paste's httpserver) and had the codebase running on WSGI! Great!
There were still some problems with SQLAlchemy, so after looking around on the web and asking on IRC, I did two things: Migrate from MyISAM to InnoDB (transaction-based SQL engine) and created a threading.Lock() object in the database access object and wrapped all database access calls between lock.acquire() and lock.release() calls. Now, SQLAlchemy is running much better and stable than before. Not only because of the changes I did, but also because the WSGI makes it possible to run one process with multiple threads (instead of multiple processes, where SQLAlchemy can't share objects between page requests).
To test my changes and to see if the server will stay stable with many concurrent requests, I installed Siege and pointed it at my local webserver. I was able to fix some miscellaneous bugs that cropped up while testing with Siege, and also had statistics on how fast a page would be generated. On my 2GHz (2GB RAM) MacBook, the first photo overview page loaded for about 6 to 15 seconds (HTML only), depending on load. This was way too long, so I thought about implementing some kind of cache.
I'm now caching certain pager data that can be cached and doesn't depend on users being logged in or not. This reduces the page load time to about 0.3 seconds (HTML only, again), so perli.net should be a bit faster on certain pages. A good space-time tradeoff, I think :)
Saturday, July 28, 2007
Announcing python-jabberbot
I've just released the first version of python-jabberbot, a simple framework to easily write Jabber bots in Python. The framework utilizes the wonderful xmpppy library for the XMPP protocol and was inspired by the xmpppy library bot.py example, although my implementation is targeted at users wanting to simply implement some bot functionality in Python without much hassle.
To implement a bot with python-jabberbot, simply subclass the provided JabberBot class and add some methods to your class that start with "bot_", i.e. "bot_status". The method will receive three parameters: The "self" object, a "mess" object that is the message being received by the client and an "args" object which is a string and contains the parameters given to the jabber bot.
A basic example that returns some system information can be found on the website and a more advanced example showing how to do multi-threading and message broadcasting can be found here. This one has been Aanice afternoon time killer - I hope this is useful to somebody someday :)
To implement a bot with python-jabberbot, simply subclass the provided JabberBot class and add some methods to your class that start with "bot_", i.e. "bot_status". The method will receive three parameters: The "self" object, a "mess" object that is the message being received by the client and an "args" object which is a string and contains the parameters given to the jabber bot.
A basic example that returns some system information can be found on the website and a more advanced example showing how to do multi-threading and message broadcasting can be found here. This one has been Aanice afternoon time killer - I hope this is useful to somebody someday :)
Sunday, July 22, 2007
Yeah! UTF-8 and Unicode in Py3k!
From what I just read on GvR's Python 3000 Status Update, it seems like loads of problems that crop up when using non-ASCII characters in string literals will be finally gone in Python 3.0. While developing the new perli.net codebase, this has been a problem, as everything (database + code + HTML output) is UTF-8 encoded, and if you are not careful enough, Python 2.4 will bite you with an exception (string literals containing umlauts, etc..).
Having UTF-8 as the default source encodings will make things easier for code with non-ASCII string literals. That's one of the quirks I dislike about the current Python. I'm glad this problem is taken care of in Python 3.0.
Having UTF-8 as the default source encodings will make things easier for code with non-ASCII string literals. That's one of the quirks I dislike about the current Python. I'm glad this problem is taken care of in Python 3.0.
The broken Canon Digital IXUS 60
Yesterday evening, my Canon Digital IXUS 60 camera's lens got stuck, and so the camera stopped working altogether. Luckily, I was able to copy all pictures from the camera with a simple pnm-fetch, so at least the photos, videos and audio files (yeah, I tried that the first time yesterday ;) are safe. The error message (in German) was "Objektivfehler:Kamerarestart", an error which is famously known as the "E18 error".


Thanks to my sister, I can now try out her Casio Exilim EX-S770, which looks really slick and is thinner than the Digital IXUS 60. Now that I am very disappointed with the Canon brand cameras, I can try out how good the Casio is. I'll bring the IXUS back to the shop where I bought it in September 2006, and hopefully they will be able to fix it.
After some fiddling, I can get the IXUS to open the lens a bit and make photos, but they are badly unfocused, as you can see in this picture:



Thanks to my sister, I can now try out her Casio Exilim EX-S770, which looks really slick and is thinner than the Digital IXUS 60. Now that I am very disappointed with the Canon brand cameras, I can try out how good the Casio is. I'll bring the IXUS back to the shop where I bought it in September 2006, and hopefully they will be able to fix it.
After some fiddling, I can get the IXUS to open the lens a bit and make photos, but they are badly unfocused, as you can see in this picture:

Thursday, July 19, 2007
Python-ish Spambot Checker Code
I'm the maintainer and webmaster of PERLI.NET, and as such, I have to make sure publicly-available forms for user-submitted entries are spambot-proof. If I was way too Web2.0-ish, I'd be using reCAPTCHA, but as this would make my website rely on that service, and because I already had some fool-proof solution to that problem, I decided to re-implement my old "Enter this number:" checker, this time in Python:
This function takes a number in the range 0-99 and returns a string representation of it, as it would be spoken in German (the main audience of PERLI.NET is German-speaking). Now, I'm displaying the returned string (for example "einunddreißig") on the guestbook entry form and also include a hidden field that has the answer encoded (I'm using the simple method of multiplying the number by two, but you might chose a more sophisticated algorithm). I'm also displaying a text entry box where the user types in the number.
The guestbook entry is only saved when the number is keyed in correctly, if not, the entry is silently ignored. That should save you some guestbook-entry-deleting work and make your visitors happy! You can view the resulting guestbook entry form here.
def number2german( num):
"""Convert a number to a German string
Convert a number to a German string, as it would be
spoken aloud. Valid range: 0 - 99
"""
specials = {0:'null',1:'eins',11:'elf',12:u'zwölf',
16:'sechzehn',17:'siebzehn'}
tens = ['','zehn','undzwanzig',u'unddreißig','undvierzig',
u'undfünfzig','undsechzig','undsiebzig',
'undachtzig','undneunzig']
ones = ['null','ein','zwei','drei','vier',u'fünf',
'sechs','sieben','acht','neun']
if num in specials.keys():
return specials[num]
if num < 0 or num > 99:
return ''
if num % 10 == 0:
if tens[num/10][:3] == 'und':
return tens[int(num/10)][3:]
else:
return tens[int(num/10)]
return u'%s%s' % ( ones[num%10], tens[int(num/10)], )
This function takes a number in the range 0-99 and returns a string representation of it, as it would be spoken in German (the main audience of PERLI.NET is German-speaking). Now, I'm displaying the returned string (for example "einunddreißig") on the guestbook entry form and also include a hidden field that has the answer encoded (I'm using the simple method of multiplying the number by two, but you might chose a more sophisticated algorithm). I'm also displaying a text entry box where the user types in the number.
The guestbook entry is only saved when the number is keyed in correctly, if not, the entry is silently ignored. That should save you some guestbook-entry-deleting work and make your visitors happy! You can view the resulting guestbook entry form here.
Sunday, July 15, 2007
Exaile: Python-based GTK media player
I don't know on which planet I got linked to Exaile, a GTK audio player written in Python. Anyway, I installed it some days ago and downloaded some plug-ins (IM status, which works great with Pidgin; and Mini Mode, which makes Exaile about as high as the Gnome panel and only about one third of my screen wide).
Exaile is great, it has a slick, but simple interface, nice features (the music library is created by adding paths to my music collections, which is a no-nonsense way of managing the library ;). Bulk downloading album art and album cover search are great features. Last.fm integration is built-in, and DAAP support can be enabled by installing a plug-in.
There are still some annoyances: For example, tracks with no album set are displayed as "Trackname from by Artist", i.e. the album title is simply missing. But thanks to the great build/run architecture of Exaile that makes it possible to patch and test/debug directly in the SVN working directory, I was quickly able to come up with a patch, which will hopefully be included in Exaile soon.
Other than that, I can only recommend Exaile. It is in active development, and the problems and bugs that are currently present will hopefully be patched out in future versions :)
Exaile is great, it has a slick, but simple interface, nice features (the music library is created by adding paths to my music collections, which is a no-nonsense way of managing the library ;). Bulk downloading album art and album cover search are great features. Last.fm integration is built-in, and DAAP support can be enabled by installing a plug-in.
There are still some annoyances: For example, tracks with no album set are displayed as "Trackname from by Artist", i.e. the album title is simply missing. But thanks to the great build/run architecture of Exaile that makes it possible to patch and test/debug directly in the SVN working directory, I was quickly able to come up with a patch, which will hopefully be included in Exaile soon.
Other than that, I can only recommend Exaile. It is in active development, and the problems and bugs that are currently present will hopefully be patched out in future versions :)
Thursday, July 12, 2007
Trading services that serve me well
There's so much Web 2.0 going on recently that I really see something big coming our way. The biggest "me, me!" of the last two or so years is getting some internet service going, think of some funky name, leave out the last vowel, throw in tagging, rating and user accounts with some fancy API (well, here's what I really love about Web 2.0: JSON and XML and all the REST-based stuff are really easy to understand, easy to implement and standards-based - see my python-youtube client for a trivial example). There are lots of examples out in the wild.
Of course, some services are really neat - I've talked about Doodle before, and Last.fm is nice for finding related music and having an automatically generated "toplist" of songs, possibly spread over many machines, iPods and music player, because all can interface with Last.fm.
There are other services in my favourites list that are not really Web2.0-ish, but have been around for a long time. The fact that these services are still around gives you a clue about their usefulness:
GameTZ, the Game Trading Zone is a service where one can list games (+hardware), movies, books and music to form a "available" list and list things they want to have (the "wanted" list). The website makes it easy to find matches which can then result in an offer being sent. Offer history is kept on the website (some kind of dialog between the two traders) and after an agreement has been made, the offer can be transformed into a trade, which will then be pending until both sides of the trade mark it as "received". A trade is usually followed by rating the other side of the trade. Really cool, and I've already made good trades on this site. My profile can be found here if you want to have a look.
The next service I really like (although I haven't used it recently) is db.etree.org, the Trader's Database. It's basically something like GameTZ (only the listing part, not the offer/trade/rate part), but for lossless live concert recordings. Many artists allow their fans to swap live recordings of their concerts in lossless formats over the Internet, and the Trader's Database makes this very easy. With special features like AJAX-based search and metadata that are useful for trading live music, it's really nice and easy to find shows on the 'net.
All these services come without any API and have all their vowels in place (or at least there are no vowels to leave out). Still, they rock. I hope when all the Web2.0 hype is over, that these services will survive.
Of course, some services are really neat - I've talked about Doodle before, and Last.fm is nice for finding related music and having an automatically generated "toplist" of songs, possibly spread over many machines, iPods and music player, because all can interface with Last.fm.
There are other services in my favourites list that are not really Web2.0-ish, but have been around for a long time. The fact that these services are still around gives you a clue about their usefulness:
GameTZ, the Game Trading Zone is a service where one can list games (+hardware), movies, books and music to form a "available" list and list things they want to have (the "wanted" list). The website makes it easy to find matches which can then result in an offer being sent. Offer history is kept on the website (some kind of dialog between the two traders) and after an agreement has been made, the offer can be transformed into a trade, which will then be pending until both sides of the trade mark it as "received". A trade is usually followed by rating the other side of the trade. Really cool, and I've already made good trades on this site. My profile can be found here if you want to have a look.
The next service I really like (although I haven't used it recently) is db.etree.org, the Trader's Database. It's basically something like GameTZ (only the listing part, not the offer/trade/rate part), but for lossless live concert recordings. Many artists allow their fans to swap live recordings of their concerts in lossless formats over the Internet, and the Trader's Database makes this very easy. With special features like AJAX-based search and metadata that are useful for trading live music, it's really nice and easy to find shows on the 'net.
All these services come without any API and have all their vowels in place (or at least there are no vowels to leave out). Still, they rock. I hope when all the Web2.0 hype is over, that these services will survive.
Wednesday, July 11, 2007
Subscribing to podcasts in gPodder
Until today, gPodder users were presented the same dialog for adding and editing "channels" (i.e. podcast subscriptions). When adding a channel, only the URL was needed, so all other UI elements were simply hidden in the dialog. As adding a channel only involves entering one URL, and as our new, shiny channel navigator adds some free space in the lower left corner of the window, I decided to re-work the GUI, inspired by Tasks's main window. Here's the difference:
 Of course, with this change, I also had the chance to revise the channel edit dialog a bit (remember, it's the same dialog, used for both adding and editing). Apart from stripping out unneeded code and re-factoring the code, I've tried to make the dialog a bit more pleasant to use. For one, I've removed the cancel button and changed the "OK" button into a "Close" button.
Of course, with this change, I also had the chance to revise the channel edit dialog a bit (remember, it's the same dialog, used for both adding and editing). Apart from stripping out unneeded code and re-factoring the code, I've tried to make the dialog a bit more pleasant to use. For one, I've removed the cancel button and changed the "OK" button into a "Close" button.
 I hope you like the changes and it makes using gPodder a little bit more pleasant. Time to roll another release some time soon..
I hope you like the changes and it makes using gPodder a little bit more pleasant. Time to roll another release some time soon..
 Of course, with this change, I also had the chance to revise the channel edit dialog a bit (remember, it's the same dialog, used for both adding and editing). Apart from stripping out unneeded code and re-factoring the code, I've tried to make the dialog a bit more pleasant to use. For one, I've removed the cancel button and changed the "OK" button into a "Close" button.
Of course, with this change, I also had the chance to revise the channel edit dialog a bit (remember, it's the same dialog, used for both adding and editing). Apart from stripping out unneeded code and re-factoring the code, I've tried to make the dialog a bit more pleasant to use. For one, I've removed the cancel button and changed the "OK" button into a "Close" button. I hope you like the changes and it makes using gPodder a little bit more pleasant. Time to roll another release some time soon..
I hope you like the changes and it makes using gPodder a little bit more pleasant. Time to roll another release some time soon..
Monday, July 9, 2007
Visualize your last.fm history
 Oh neat! While at rk-nightly, I've found a nice web service that graphs your listening habits on last.fm. It's called LastGraph, and you can see my current graph here. Sadly, I have only set up Rhythmbox with my last.fm account, so only songs that reside in my RB playlist get picked up by the service.
Oh neat! While at rk-nightly, I've found a nice web service that graphs your listening habits on last.fm. It's called LastGraph, and you can see my current graph here. Sadly, I have only set up Rhythmbox with my last.fm account, so only songs that reside in my RB playlist get picked up by the service.
Lovely microformats
Today, I came across the microformats.org page. Not that I haven't heard about these microformats before, but today I decided to have a look at how to implement them. After reading about the hCard format, I implemented it on the user pages of the new perli.net codebase (still to be published). I also added hCard content to my about page. Another microformat I've implemented on the new perli.net codebase is hCalendar. This format lets you integrate calendar data into an event info page. The new perli.net event detail pages will offer hCalendar data, which will let you add these events directly into your calendaring application of choice.
Testing and using microformats is as simple as installing the Operator Add-on for Firefox. You can put it in the lower right corner of your Firefox window (in the status bar) and see it light up when there is microformat content on the webpage you're visiting.
Other microformats I've implemented where I thought it would be useful: rel-tag for links to tag pages and rel-home for links back to the homepage. I personally think that microformats are a GoodThing(tm), and am eager to see these formats gain more widespread use and implementation.
Testing and using microformats is as simple as installing the Operator Add-on for Firefox. You can put it in the lower right corner of your Firefox window (in the status bar) and see it light up when there is microformat content on the webpage you're visiting.
Other microformats I've implemented where I thought it would be useful: rel-tag for links to tag pages and rel-home for links back to the homepage. I personally think that microformats are a GoodThing(tm), and am eager to see these formats gain more widespread use and implementation.
Saturday, July 7, 2007
Software release cycles
Releasing software is fun. This weekend, two of my projects released a new version: wavbreaker 0.8.1 and Tennix 0.3.2. Both releases only contain a handful of bugfixes and only minor feature enhancements, and in both cases, the changes leading to the release have been available in the respective SCM repositories for a few weeks already.
In the free software world, releasing software often is important. Normally, distribution vendors only ship released versions of software, so while having all bugfixes and minor enhancements in a public Subversion repository is good for the interested developer, these updates won't reach the users of distribution packages.
Of course, releasing software is tedious work: One has to fix up README files, update version information on the project's website, submit release information to sites like Freshmeat or the FSF Directory. All this takes time, and when I'm releasing a new version of gPodder, I find myself working a whole evening while preparing everything that is needed for a release. Still, I try to release a new version of gPodder every month, if there are changes, no matter how small.
Depending on your project, you should start making up some "release plan". Commit yourself to doing one release per month and be prepared to do interim releases if you have a code rush on a project and push many changes into the codebase.
Don't fear that users of your project might get upset about a new version every four weeks. If a bug crops up in code you suppose has been released too early, you can always quickly roll another release.
Last but not least, doing a release improves publicity of your project, as it will be listed as "updated" on free software news sites (Freshmeat, etc..), users will see that the project is actively worked on and you'll have some content for the "news" section of your project's homepage.
In the free software world, releasing software often is important. Normally, distribution vendors only ship released versions of software, so while having all bugfixes and minor enhancements in a public Subversion repository is good for the interested developer, these updates won't reach the users of distribution packages.
Of course, releasing software is tedious work: One has to fix up README files, update version information on the project's website, submit release information to sites like Freshmeat or the FSF Directory. All this takes time, and when I'm releasing a new version of gPodder, I find myself working a whole evening while preparing everything that is needed for a release. Still, I try to release a new version of gPodder every month, if there are changes, no matter how small.
Depending on your project, you should start making up some "release plan". Commit yourself to doing one release per month and be prepared to do interim releases if you have a code rush on a project and push many changes into the codebase.
Don't fear that users of your project might get upset about a new version every four weeks. If a bug crops up in code you suppose has been released too early, you can always quickly roll another release.
Last but not least, doing a release improves publicity of your project, as it will be listed as "updated" on free software news sites (Freshmeat, etc..), users will see that the project is actively worked on and you'll have some content for the "news" section of your project's homepage.
Wednesday, July 4, 2007
gPodder gets new channel navigator
 My PyGTK pet project, gPodder is currently receiving a bit of a face-lift for its main window. After Carlos Moffat has raised some concern about the usability when being subscribed to many channels and suggested a "sidebar".
My PyGTK pet project, gPodder is currently receiving a bit of a face-lift for its main window. After Carlos Moffat has raised some concern about the usability when being subscribed to many channels and suggested a "sidebar". So, I first added some unread episodes information to the channel drop down list, so one can easily see where new episodes are to be found. Two e-mails later, I thought I should improve this a bit more and added a gtk.TreeView and a gtk.HPaned onto the Podcasts tab, displaying the top gtk.ComboBox's contents (thanks to the reusability of Gtk's TreeModel structures) in the left pane.
So, I first added some unread episodes information to the channel drop down list, so one can easily see where new episodes are to be found. Two e-mails later, I thought I should improve this a bit more and added a gtk.TreeView and a gtk.HPaned onto the Podcasts tab, displaying the top gtk.ComboBox's contents (thanks to the reusability of Gtk's TreeModel structures) in the left pane.The next step was adding a bit more design to the whole UI, and while fixing many bugs that cropped up while testing the new interface (and cleaning up the source code, for example unifying the new episodes algorithm into a single function), I finally had a nice-looking interface that gives the user much more information about the subscribed channels and new episodes. By using the channel's iTunes cover image (if available) as icon, a user can easily recognize specific podcast channels if the list is huge. Adding a bit of the channel's description below its title also gives a better overview over one's channels. The number in the sidebar tells us how many new podcast episodes are available for the channel. Here's how it looks currently:
 The code should be available in gPodder's Subversion repository in the upcoming days after I've cleaned up the commit a bit. Enjoy :)
The code should be available in gPodder's Subversion repository in the upcoming days after I've cleaned up the commit a bit. Enjoy :)
Web-based meeting scheduler.
Benji has just informed me that there's a nice web-based service for coordinating meetings and the like: Doodle. Just enter the possible dates, send out a link to participants and they can select the dates they are available and everybody can instantly see the results. Neat!
Tuesday, July 3, 2007
Pingback/TrackBack for Git?
Wouldn't it be cool if Pingback/Trackback (nice comparison here) could be implemented for the distributed VCS Git? As every object in Git is verified by its hash, security would be built-in, and new commits on top of the origin's master branch have to be verified by the user, anyway.
I'd see the following benefits of having something like Pingback/Trackback in Git:
I realize this could probably only implemented with gitserve repositories (i.e. git://) and ssh+git repositores, but not with "dumb" (i.e. http://) repositories, but maybe it'd be possible to add some kind of CGI (think: gitweb) addition to allow for pingbacks. If a repository stores the URL of the gitweb installation of this repository and gitweb is extended to allow saving of ping/track-back repository URLs, we could have ping/track-back for all our Git repositories.
I'd see the following benefits of having something like Pingback/Trackback in Git:
- Automatic mirror discovery to download objects from
- Upstream author has a nice overview of available branches/forks
- Stale repositories could link to recently updated repositories
I realize this could probably only implemented with gitserve repositories (i.e. git://) and ssh+git repositores, but not with "dumb" (i.e. http://) repositories, but maybe it'd be possible to add some kind of CGI (think: gitweb) addition to allow for pingbacks. If a repository stores the URL of the gitweb installation of this repository and gitweb is extended to allow saving of ping/track-back repository URLs, we could have ping/track-back for all our Git repositories.
Monday, July 2, 2007
New Tennix! website

Last Wednesday, I prepared a new website for Tennix!, my SDL-based tennis game. Tennix! has initially been developed on Borland C for DOS in 2003 as a summer project at school. The original Tennix is still available on the net.
In the middle of May this year, I've started porting the old DOS-based game (with custom-written mouse interface and 256-color bitmap laoder) to SDL. This has been quite easy, given the fact that I didn't use drawing routines back then but simply blitted BMP files onto the screen to generate the UI and gameplay graphics. Loading and blitting BMP files are two of the few graphics manipulation methods available in stock SDL.
Later, I've enhanced some graphics (scaled to 640x480) and modifed the gameplay to be real tennis-like (instead of the ping pong from 2003). In the last few weeks, I've played around with the codebase and improved the code, so I thought the project would now deserve its own webpage. Thanks to Ryan from icculus.org for providing the hosting of the new Tennix! website.
Saturday, June 30, 2007
Dreaming beyond Web 2.0.
In recent months, many "Web2.0-ish" applications have been popping up around the web. This week, I've found Shelfari, a social book listing website where users can list books they own or have read. It's a nice idea, especially for users that read a lot of books.
For every "Web2.0-ish" application out there, there is some means of integrating the content on your website/blog/etc. You can add a "My Books" box from Shelfari, have a Photostream box from Flickr or put your recently played tracks from last.fm on your website.
I don't like at least two facts about today's "Web2.0" applications:
AJAX/browser-based UI: Of course, there are frontends for Flickr, etc.. but most of the time, these services are used through the browser. For a 64k ISDN user like me, using AJAX-based applications is a drag. Desktop applications are fast and slick and have a more unified and stable UI than browser apps. What I really like to have are many small Desktop applications that interact with web services
This week, I installed Ross Burton's Tasks application (version 0.9 released last week) - a really slick tasks manager (see screenshots on website) that uses EDS as its backend store. "Tasks" is really great - it's a nicely-integrated Desktop app (and also works on mobile devices). If Tasks would interface with some web-based data store (a sort of web service-version of EDS), and this web-based data store would be accessed through WebDAV, that would be some great Web2.0-ish application/data storage setup.
Web2.0 applications currently centralize both the UI and the data store. What I'd like to see in the future are nicely-integrated, slick Desktop applications like "Tasks" that interface with web-based data stores. For the data stores, I'd like to have the option to host all my personal data on some WebDAV repository, be it on my own server or on some commercial/free web space provider. Oh, yes: and make a good WebDAV client into every browser so I can drag-and-drop files instead of using some stupid HTTP form upload.
For every "Web2.0-ish" application out there, there is some means of integrating the content on your website/blog/etc. You can add a "My Books" box from Shelfari, have a Photostream box from Flickr or put your recently played tracks from last.fm on your website.
I don't like at least two facts about today's "Web2.0" applications:
- data is stored on the service provider's servers
- accessing the data is only possible using some AJAX-/browser-based UI
AJAX/browser-based UI: Of course, there are frontends for Flickr, etc.. but most of the time, these services are used through the browser. For a 64k ISDN user like me, using AJAX-based applications is a drag. Desktop applications are fast and slick and have a more unified and stable UI than browser apps. What I really like to have are many small Desktop applications that interact with web services
This week, I installed Ross Burton's Tasks application (version 0.9 released last week) - a really slick tasks manager (see screenshots on website) that uses EDS as its backend store. "Tasks" is really great - it's a nicely-integrated Desktop app (and also works on mobile devices). If Tasks would interface with some web-based data store (a sort of web service-version of EDS), and this web-based data store would be accessed through WebDAV, that would be some great Web2.0-ish application/data storage setup.
Web2.0 applications currently centralize both the UI and the data store. What I'd like to see in the future are nicely-integrated, slick Desktop applications like "Tasks" that interface with web-based data stores. For the data stores, I'd like to have the option to host all my personal data on some WebDAV repository, be it on my own server or on some commercial/free web space provider. Oh, yes: and make a good WebDAV client into every browser so I can drag-and-drop files instead of using some stupid HTTP form upload.
Friday, June 29, 2007
Inkscape Genealogy
It just so happened that Steve wanted a new logo design for Genea, a free genealogy program. Firing up Inkscape, I quickly created a very simplistic, yet pleasing logo. The font used is "Axaxax", in case anyone wonders, and the colors are from the Tango project's color palette.
Heard today that this will very likely be the new official Genea logo soon. I've therefore licensed it under the CC Attribution-NonCommercial 2.0 license.

Heard today that this will very likely be the new official Genea logo soon. I've therefore licensed it under the CC Attribution-NonCommercial 2.0 license.

Kubezius Nickelback
As a result of service idleness this morning, here's something I've came up with to describe Nick's nickname (sic).

The Zivildiener Kubezius with his fabulous band mates. This is how you remind me.

Subscribe to:
Posts (Atom)